
Container orchestrators are the next big thing in the modern containerisation movement. And unless you have painted your career into a legacy corner, you will encounter these technologies sooner or later.
OpenShift was my introduction to this space. At that time, I was not able to find suitable online resources that truly catered to developers while being broad in scope. This series of articles is my attempt to remedy this.
The only prerequisite is a general understanding of containerisation technologies, such as Docker. And for that, there is plenty out there including previous posts on this very blog.
Open… Who?
OpenShift 3 is Red Hat’s strategic container application platform. The previous incarnations of OpenShift are radically different from version 3 and we will ignore them for most parts.
For this version, Red Hat has opted to curate a set of existing open-source projects into a single best-of-breed platform. At its heart is Kubernetes, a mature and resilient container orchestration technology, open-sourced by Google.
Think of OpenShift as a single unified view, draped over a collection of application nodes, like physical servers or cloud instances. You ask the platform to “schedule” a container and it will check the nodes for a suitable location with enough resources and proceeds to deploy your container there. Subsequently it monitors the container, ensuring it remains active or is moved elsewhere if the entire application node tragically expires.
OpenShift currently comes in the following flavours:
- OpenShift Origin: The open-source upstream project
- OpenShift Container Platform (OCP) or OpenShift Enterprise (OSE): The on-premise commercially-supported version
- OpenShift Online: Consumer-level OpenShift cloud, managed by Red Hat
- OpenShift Dedicated: Enterprise-level OpenShift cloud, managed by Red Hat
The architecture, as far as a developer is concerned, is almost identical between the above offerings but it is worthwhile to mention my personal experience has been primarily with the first two.
Concepts & Terminology
OpenShift introduces a few novel concepts and terminologies that any self-respecting developer should understand. We can very well launch into a lengthy philosophical discussion of each concept till we can’t see the forest for the trees but I did promise the big picture; so:
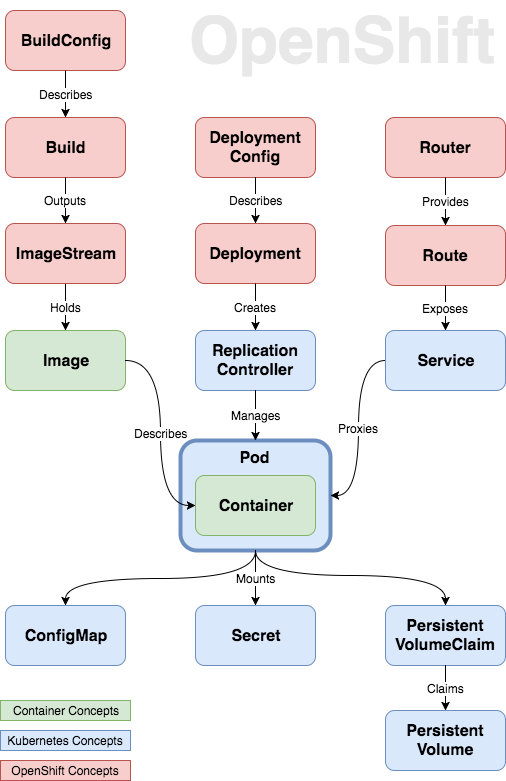
As the diagram suggest, Pods are the centrepiece of this architecture. A pod is simply a collection of one or more containers deployed to an application node.
I divided the rest of the concepts into 4 pillars: Build, Deploy, Expose and Store.
Build
The goal of this phase is to produce a container image.
We start with the blueprint for our Build, the BuildConfig. When a build is triggered, the platform generates an image based on that blueprint and stores it in an ImageStream, a collection of images.
Deploy
The goal of this phase is to produce a running pod.
Similar to its build counter-part, a DeploymentConfig prescribes how the containers should be deployed. When a Deployment is triggered, it creates a Replication Controller, tasked with starting the pod and ensuring its continuous survival.
Expose
A pod can run on any of application node but it should still be accessible to internal and external consumers transparently.
A Service load-balances the communication to a pod, providing a constant endpoint. Additionally developers can define Routes to allow external HTTP/WebSocket requests to reach the pod. A collection of Routers enable this functionality.
Store
There are two main methods of injecting configuration into containers: 1) as environment variables, or 2) as volumes mounted into containers.
ConfigMaps and Secrets are basically hashmaps that can be converted to either of above mechanisms. As the name suggests, Secrets provide an additional level of encoding over ConfigMaps to obscure the content.
Containers are also traditionally ephemeral but it would be naive to assume that so are all applications. OpenShift provides Persistent Volumes, backed by various storage providers, that pods can “claim” and mount into the containers.
Bonus
Since I am in a generous mood, I will throw in some additional concepts:
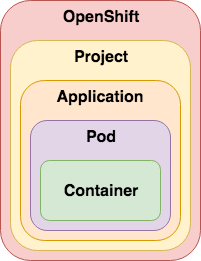
An OpenShift cluster can be subdivided into multiple Projects. All the above mentioned objects can be segregated into these namespaces.
Another powerful mechanism is the use of labels to provide metadata on any OpenShift object. One standard label is the concept of Application that can be used to group different objects that make up an functioning application.
Shallow Dive
I am under no illusion that OpenShift is a complex beast. The high level discussion so far leaves out many details and I understand if some of this feels like black magic to the reader. While I am not certain of any actual occult involvement, many of the features are implemented in a very straight-forward manner.
In this section, I would like to dig in a bit into the guts of the platform and take a peek at how it achieves some of its functionality.
Build
OpenShift creates a Builder Pod when a build is triggered. This is privileged container that interacts with the Docker daemon, performing similar actions to a docker build.
ImageStreams keep track of all previous builds of an image tag by recording the image layer digests.
See Builds and ImageStreams for more information.
Deploy
Similar to the build, a Deployer Pod is created during a deployment trigger. This pod in turn creates the aforementioned Replication Controller.
Pods themselves are in reality one or more containers running on a shared virtual network and storage infrastructure. Their entire lifecycle is managed by Replication Controllers.
See Pods and Services for more information.
Expose
OpenShift provides its unified networking by leveraging a Software-Defined Network (SDN). Open vSwitch is the technology that enabled this overlay network.
The routing in OpenShift is enabled by set of HAProxy containers. By default, you can find these in the default project in OpenShift.
See Networking for more information.
Store
ConfigMaps and Secrets are made available to pods via a temporary filesystem (tmpfs).
It is worthwhile to note that Secrets are not encrypted but simply hashed. Role-Based Access Control limits their access in the projects. OpenShift provides encryption at rest from version 3.6.1 onwards.
Persistent Volumes are typically created by cluster administrators on top of networked storage solutions, such as NFS, GlusterFS, AWS EBS, etc. Developers can then create a Persistent Volume Claim to attach the volume to one or more pods.
See Other API Objects for more information.
Bonus
The above objects are typically referred to as API Objects as both Kubernetes and OpenShift provide APIs to interact with them. Each object has a set of attributes that define its characteristics.
You will often encounter these object definitions in JSON or YAML structures. All objects at least define following:
apiVersion: "v1"
kind: "Pod"
metadata:
name: "my-pod"
...apiVersiondefines the version of the Kubernetes/OpenShift API that the object complies withkindidentifies the object, e.g.Service,Secret, etc.metadatacontains the labels that is attached the object, including itsname
And we’re done!
Hopefully this condensed guide has started you on the path of learning OpenShift and using its immense power to deliver resilient application platforms.
In the next installment, we start to get our hands dirty with OpenShift.