
In today's hyperconnected world, businesses are inundated with vast amounts of data streaming in from a multitude of sources at unprecedented speeds. From customer interactions to machine-generated telemetry data, the sheer volume and velocity of this data present both opportunities and challenges for organisations striving to stay ahead in today's competitive landscape.
Imagine this scenario: a leading e-commerce platform experiences a surge in website traffic during a flash sale event, with thousands of customers simultaneously browsing products, adding items to their carts, and making purchases. In the midst of this flurry of activity, the platform's traditional data processing systems struggle to keep pace, resulting in delays in order processing, inventory updates, and customer notifications. As a result, frustrated customers abandon their carts, leading to missed revenue opportunities and damage to the brand's reputation.
However, amidst these challenges lies a transformative solution: event streaming. As mentioned in this blog, event streaming is an investment you make to reduce the latency between data generation and the insights that you derive out of that data. By harnessing the power of real-time data streaming, organisations can unlock invaluable insights, enhance operational efficiency, and deliver seamless customer experiences like never before.
A Note about Event Streaming
We are used to seeing the Publisher/Subscriber model everywhere these days. Companies have been adopting it en-masse for scalability, reliability and ability to decouple interfaces. While we love everything event driven, graduating from simple pub/sub models to a full blown event driven ecosystem changes your perspective on event streaming. This model takes the concept of events and embraces the continuous movement of data to drive value with dynamic and adaptable systems.
Embracing the potential of event streaming means bringing your business logic into the realm of real-time and enabling the composition of richer data outputs than would be otherwise possible. Event streaming allows you to continuously consumer and produce new data streams for others to use. In a world where meaningful and effective analytics bolster insights into business domains, event streaming enables teams to bring more value with less effort, and identify and adapt to emerging opportunities.
Apache Kafka has become the go-to standard in designing event driven systems. Kafka Streams is a Java library that provides a high level DSL for creating and composing stream processing applications. Deploying boilerplate heavy Java apps can be time consuming when handling basic stream logic. To get from idea to deployment you have to:
-
Start your Java project
-
Set up your build system and dependencies
-
Write your app configuration boilerplate
-
Get your DSL pipeline set up
-
Write your business logic
-
You had better be testing here
-
Build your container
-
And be testing here
-
Deploy your container
-
Manage your service availability indefinitely
We are building at a time where developing features and value in our data streams is the key to gaining a competitive advantage on the competition. With so many steps required to bring new ideas into the hands of downstream teams, developers have been rapidly adopting a new workflow.
Enter Flink
Apache Flink is a unified stream and batch processing framework that has been a top-five Apache project for many years. Apache Flink has a strong, diverse contributor community backed by many companies. Flink empowers us to leverage the power of streaming by operating natively inside our event streaming systems. When compared to typical containerised deployments, we are able to shorten the feedback loop from idea, to POC, to production environment. With this capacity to change, expand and create better systems, we are able to ship features for clients far more easily than in a typical development cycle. These advantages extend both internally, to our integration, and attached systems, as well as externally to the data products we share with other teams and services.
Some of the benefits Flink provides over typical streaming applications include:
-
Massive Concurrency thousands of workers can operate in parallel, scaling to handle data dips and spikes, all from a single point of administration. Flink also uses its native support for event processing and efficient state management to provide low-latency processing for real-time data analytics and decision making logic.
-
Fault Tolerance Flink automatically and asynchronously generates checkpoints to ensure that processing can resume unhindered in the event of hardware outages or network issues. This resilience in the face of failures ensures data correctness, always.
-
Efficient Interfaces Flink SQL provides a unified interface for batch and stream processing. Data engineers are able to reuse code more often, with less deployment overhead. Flink SQL is ANSI-SQL compliant, which means if you’ve ever used a database in the past, you already know it.
Easily build high-quality, reusable data streams with the industry’s only cloud-native, serverless Flink service
And now, we’re thrilled to be partnered with Confluent as they announce the general availability of the industry’s only cloud-native, serverless Apache Flink® service. Available directly within Confluent’s data streaming platform alongside a cloud-native service for Apache Kafka®, the new Flink offering is now ready for use on AWS, Azure, and Google Cloud. Confluent’s Apache Flink service is a simple solution for accessing and processing data streams from across the entire business to build a real-time, contextual, and trustworthy knowledge base to fuel applications.
Fully integrated with Apache Kafka® on Confluent Cloud, Confluent’s new Flink service allows businesses to:
-
Effortlessly filter, join, and enrich your data streams with Flink, the de facto standard for stream processing
-
Enable high-performance and efficient stream processing at any scale, without the complexities of infrastructure management.
-
Experience Kafka and Flink as a unified platform, with fully integrated monitoring, security, and governance
With all these advantages, we also get another bonus. Simplicity. In this blog we will be using an interactive example to explore the process of migrating a Kafka Streams task onto Confluent Flink, streamlining our system and yielding the scalability, resilience, and capacity for rapid iteration that comes with it.
Finding Our Baseline
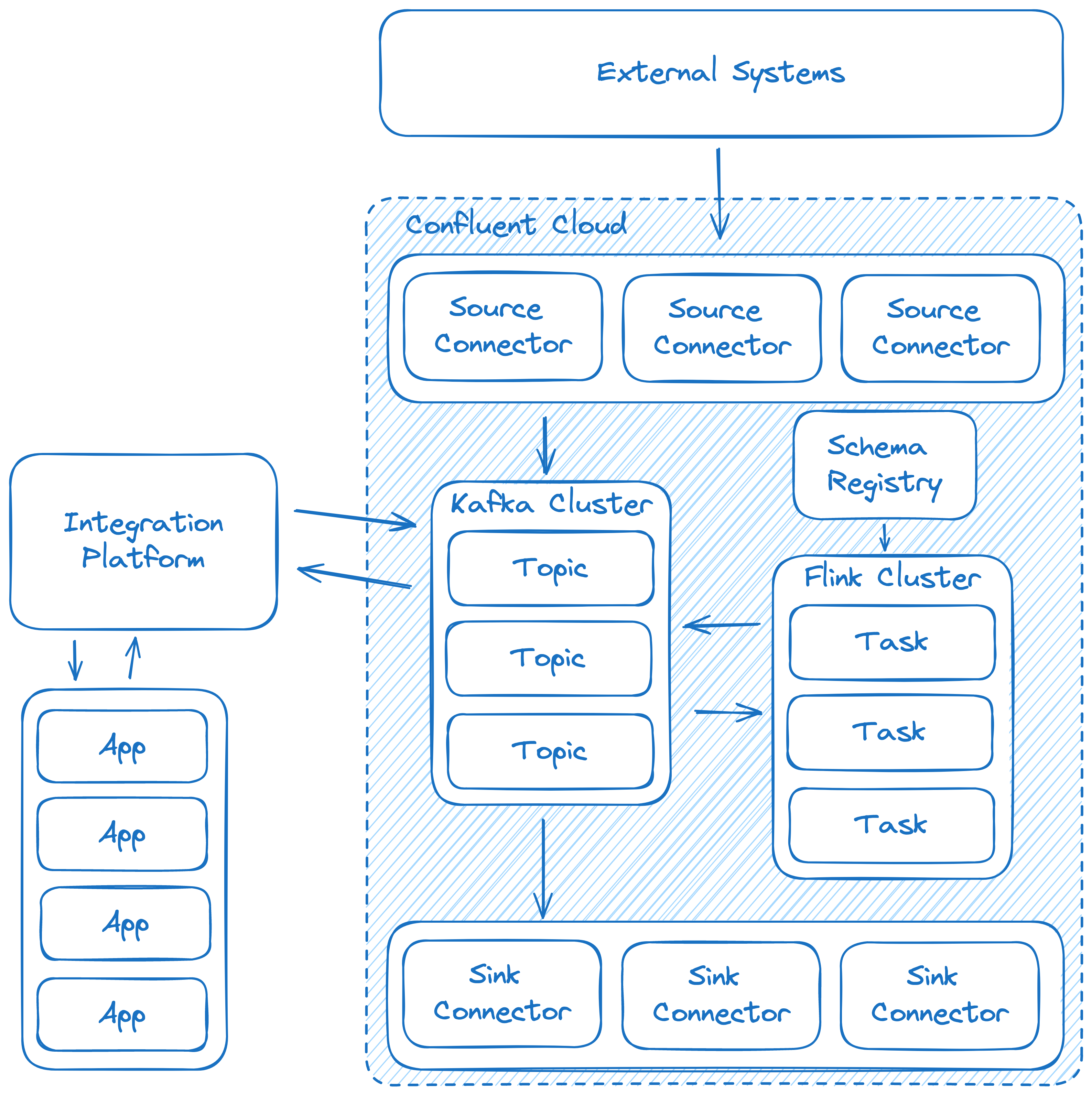
Below is the architecture we will be using for an example Flink refactor. We have several source connectors that ingest data from our persistent data stores. We have our cluster set up and our topics are governed by a Schema Registry instance to ensure data integrity. Our user facing applications interact with the wider ecosystem through an integration layer. And finally our event processing is handled by a series of Kafka Streams applications, hosted on a managed Kubernetes cluster.
sss.png?width=4172&height=3184&name=kafka-blog-architecture-after(1)sss.png)
While this architecture is great, all of our stream processing resides outside of our streaming domain. One of the main tenets of event streaming is processing data where it resides. Throughout this blog we will be bringing the benefits of Confluent Flink, into our application and the benefits that come along with it. So, lets…
Get Started
In order to get started with Flink, navigate to any existing Confluent Cloud environment and click on the newly rendered ‘Flink’ tab. From here you can add a compute pool and follow the prompts to get your first compute cluster enabled.
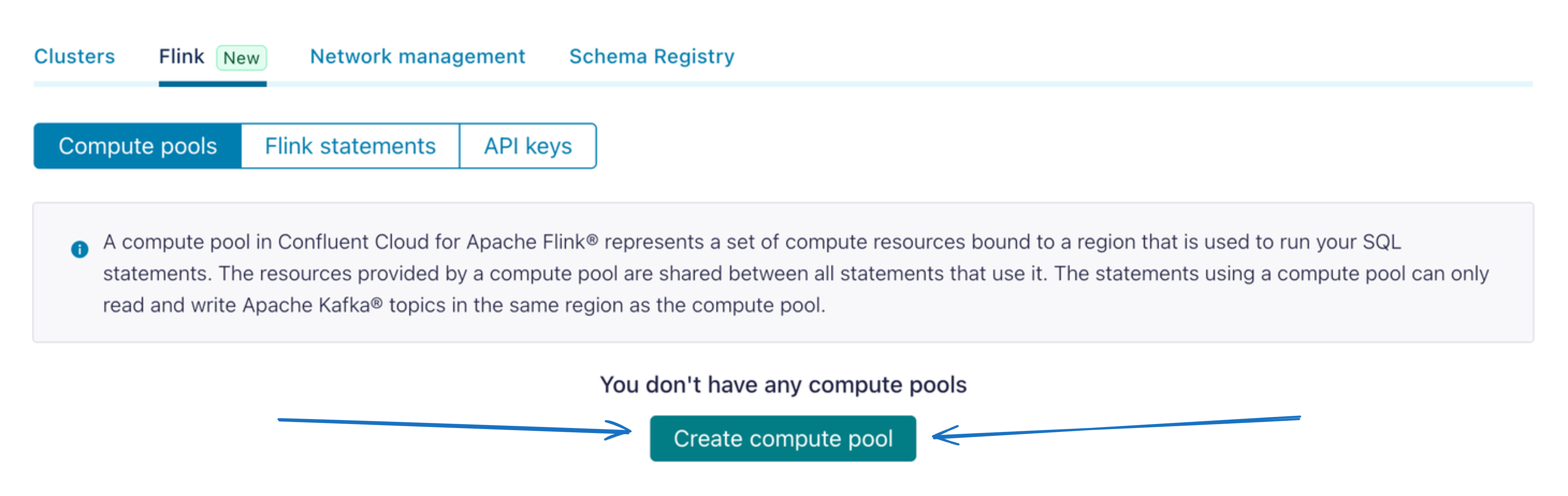
Its that easy!
While Confluent has a fantastic UI that we can use to build our systems, they also provide a fantastic Terraform provider to help streamline infrastructure lifecycle management. This provider is power consistent, reproducible deployments of our environment, clusters, governance, and RBAC in Confluent Cloud. Considering we are managing our lifecycle this way, we are going to add this compute pool to our IaC script.
If we look as the API reference for the Confluent Terraform provider, we can see that Confluent have already added a resource for us to use, you can find the documentation here.
If we add the following snippet to our Terraform script:
resource "confluent_flink_compute_pool" "core_compute_pool" {
display_name = "core_compute_pool"
cloud = var.cloud_provider
region = var.deployment_region
max_cfu = 5
environment {
id = confluent_environment.example_environment.id
}
}
terraform apply we should find our newly created resource in Confluent Cloud.We now have a Flink compute pool, ready to go, out of the box. No resource allocation or task manager setup. We don’t have to worry about scaling, and most of all, we don’t need to worry about entity and user permission! With 9 lines we are ready to start refactoring our pipeline.
How Flink Handles Topics
Confluent Flink operates on topics as first class data tables, if you have used ksqlDB then this will be familiar to you. Not only are we able to create new topics governed by schema registry using Flink SQL syntax, our Flink tasks are ready to use our existing topics and their corresponding schemas. Confluent Flink leverages the stream governance packages provided by Confluent to index and arrange all of the data sources present in your Confluent Cloud environment. This presents an immensely powerful tool for shaping data in your organisation.
If you look at your Flink SQL workspace, you would be surprised that you hadn’t somehow stumbled into a data cataloging platform. Each existing topic is available, linking directly to its corresponding lineage, schema, metadata and feed.
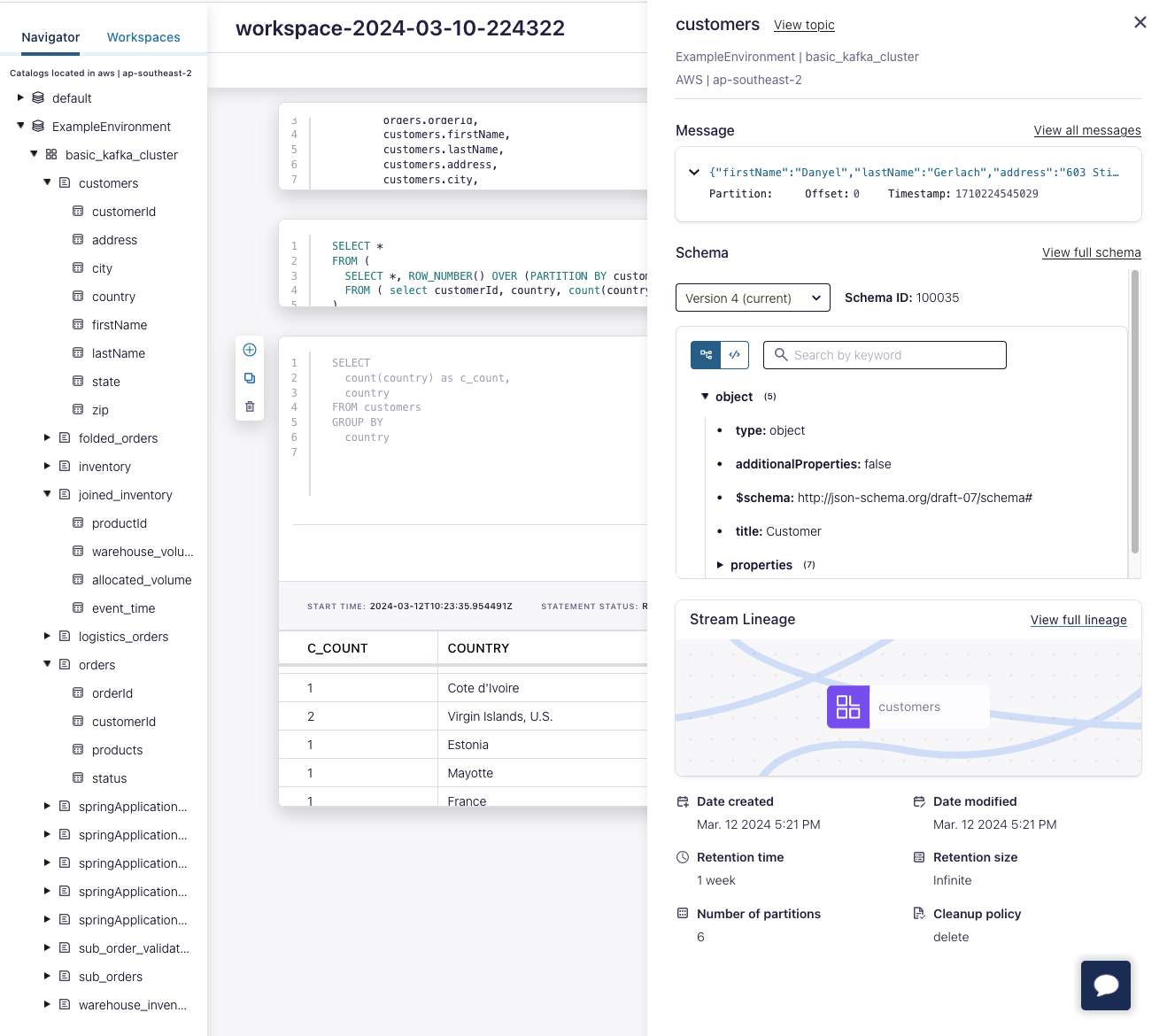
What Are Data Catalogs, and Why We Need Them
A data catalog is an inventory of data assets that allow engineers to quickly find appropriate data sources. It provides metadata management, and describes the lineage, ownership and usage of those data assets.
This centralised model of data management:
-
Enhances data accessibility, reducing the time engineers spend wrangling with data, improving overall productivity.
-
Improves data quality and consistency enabling users to make informed decisions, ensuring data consistency across assets.
-
Optimises data monetisation and innovation by unlocking the full potential of assets and enabling rapid experimentation.
Data catalogs are the linchpin of modern data management strategies, and the Confluent Flink workspace provides a holistic approach to this kind of data discovery, management, and governance.
Our Example Streams Application
Our streams app is performing a simple filter and join operation over our orders stream. After an order has been allocated by the inventory system, any allocated orders are joined with their corresponding customer data for downstream consumers to handle.
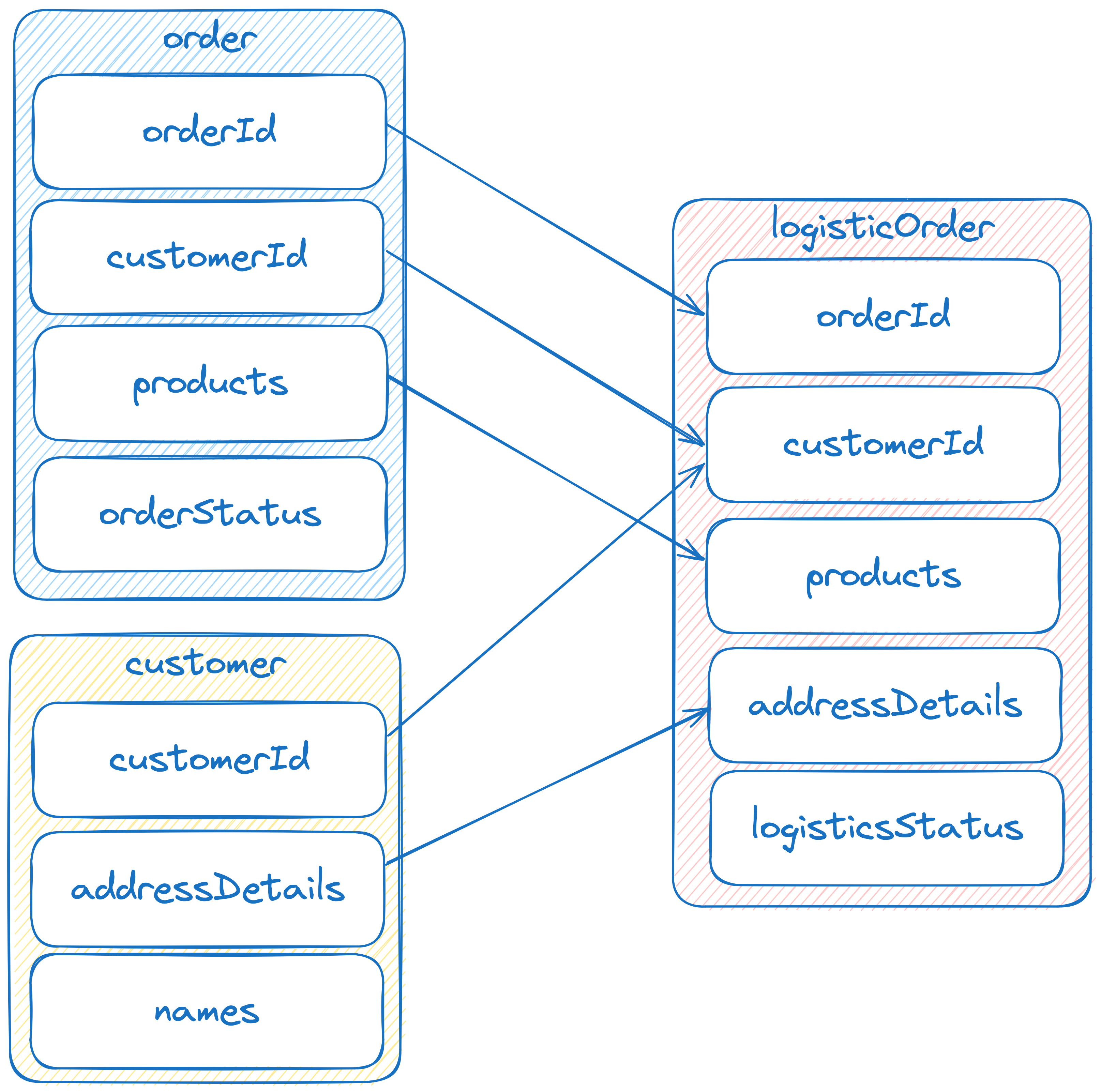
When you examine the business logic of our Java code, the operation is relatively straightforward. We have some setup to get our stream application ready, we initialise our table, prep our stream, and perform our join.
// Some Boilerplate
StreamsBuilder builder = ...
var customers_topics = ...
var orders_topic = ...
var logistics_order_topic = ...
var customers = builder.globalTable(customers_topics);
var orders = builder.stream(orders_topic);
orders.filter(
(k, v) -> v.getStatus().toString().equals(OrderState.ALLOCATED)
).join(
customers,
(k, v) -> new CustomerId(v.getCustomerId()),
(order, customer) -> LogisticsOrder.newBuilder()
.setFirstName(customer.getFirstName())
.setLastName(customer.getLastName())
.setAddress(customer.getAddress())
.setCity(customer.getCity())
.setCountry(customer.getCountry())
.setState(customer.getState())
.setZip(customer.getZip())
.setStatus(order.getStatus())
.setProducts(order.getProducts())
.build()
).to(logistics_order_topic);Our Flink Workflow
Lets get to work on our Flink task. Typically, as we are now the data owner, we would be in control of the output form. For this purpose, creating a governed stream is as simple as writing a SQL table creation DDL. If we are creating a key-partitioned stream, we can treat the primary key as our Kafka record key. Running this query in the Confluent Flink SQL editor will create the topic in our cluster, and our table schema in Schema Registry for us.
CREATE TABLE IF NOT EXISTS logistics_orders (
orderId BIGINT NOT NULL,
firstName VARCHAR(32) NOT NULL,
lastName VARCHAR(32) NOT NULL,
address VARCHAR(64) NOT NULL,
city VARCHAR(64) NOT NULL,
state VARCHAR(64) NOT NULL,
country VARCHAR(64) NOT NULL,
zip VARCHAR(64) NOT NULL,
status VARCHAR(16) NOT NULL,
products ARRAY<
ROW(productId BIGINT, volume BIGINT)
> NOT NULL,
PRIMARY KEY (orderId) NOT ENFORCED
)
However, as we are refactoring an existing service, we will reuse our existing output topic. Using our Flink SQL workspace, we can inspect the relationship between our data inputs and outputs. As engineers build new queries from scratch this insight becomes an invaluable resource.
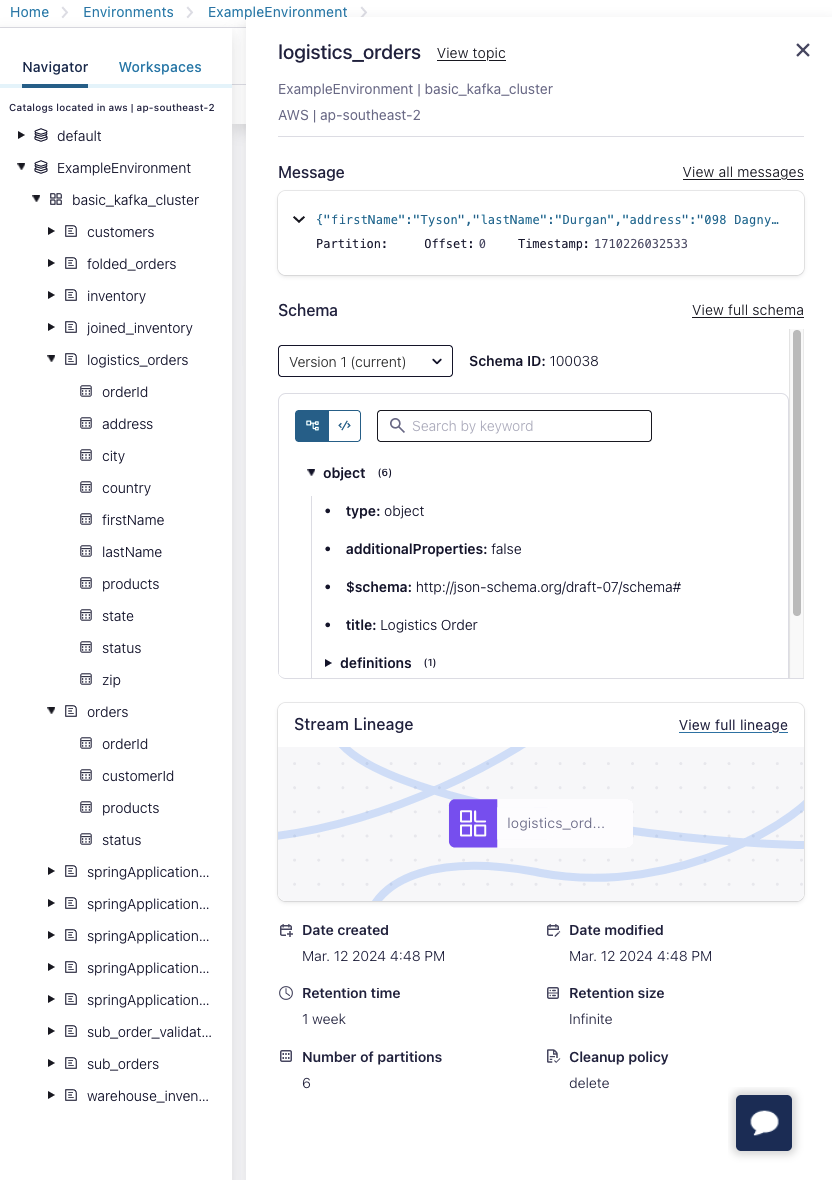
We can analyse our data sources and sinks, and begin to build our query. Our to function call is replaced by wrapping our stream in an INSERT statement. Next we can easily perform our INNER JOIN over all orders with a corresponding customer record. Finally, we can filter our our stream for only orders that currently have an ALLOCATED status.
INSERT INTO logistics_orders (
SELECT
orders.orderId,
customers.firstName,
customers.lastName,
customers.address,
customers.city,
customers.state,
customers.country,
customers.zip,
status,
orders.products
FROM orders
INNER JOIN customers ON customers.customerId=orders.customerId
WHERE orders.status='ALLOCATED'
)
And that’s it! We’ve managed to condense the number of lines in our business logic by half.
Not only have we simplified 30+ lines of Java (plus boilerplate!) into a 10 line SQL query, we have removed a task from our previous development lifecycle. We no longer have to maintain, build, store images, and run deployment pipelines for this part of our application!
Say it Once
Behind the curtain of our Java example is a swath of boiler plate and setup, before we begin to prepare our business logic. With all that setup we gain unbelievable power to shape streams in complex and innovative ways. But what goes into a running production instance that provides value to our ecosystem?
A lot.
The hard truth is that simple elements of our core business are pain to deploy and are slow to iterate. If our friendly neighborhood data engineer is hacking away with SQL queries, they will be able to see the possibility of a new feature before a heavy duty app has compiled.
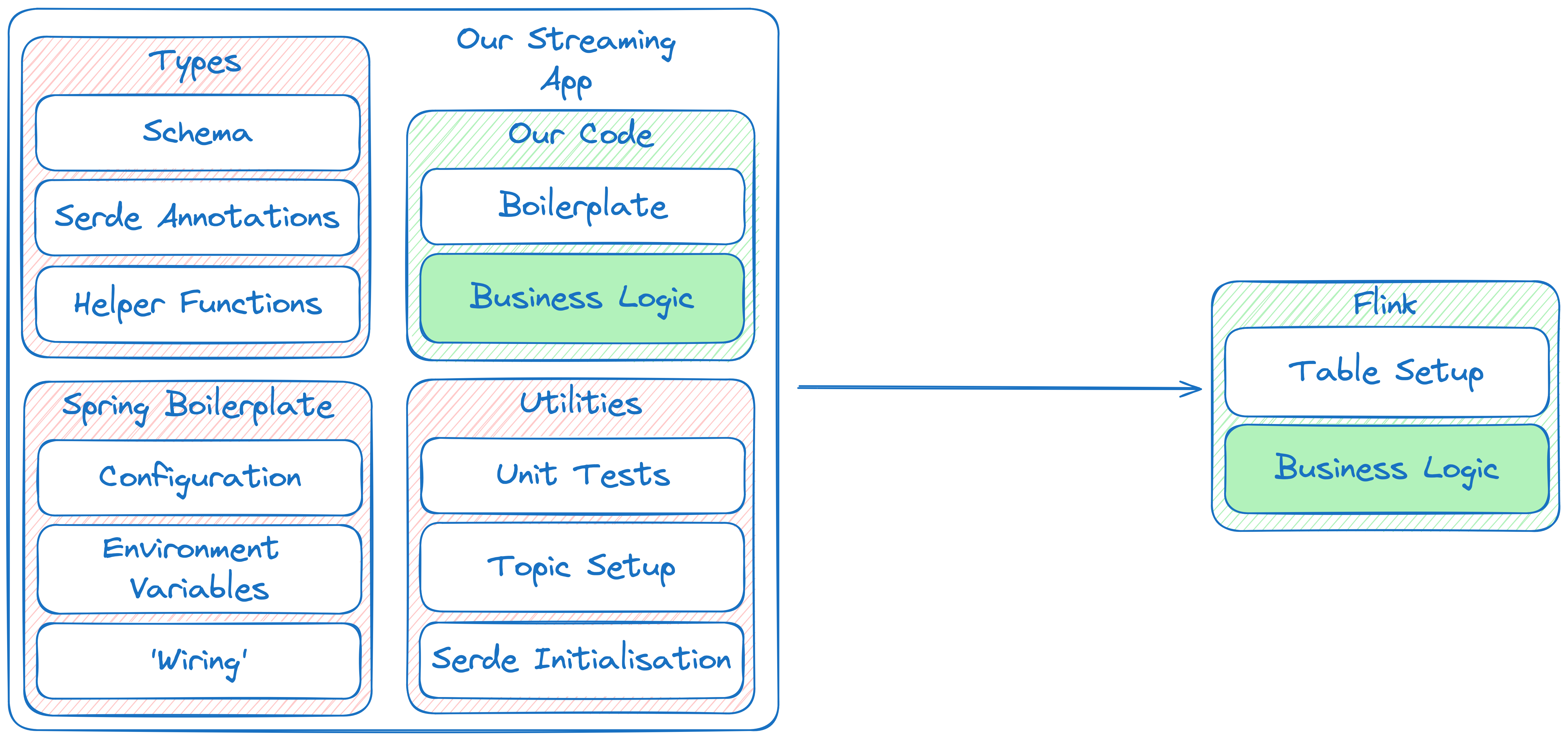
While complex business logic will always carve out a space for more involved streams applications, the sheer simplicity of the Confluent Flink platform leaves something to be very much desired in modern event streaming systems.
Expanding on Our System
Now that we have examined the Flink workflow, and the advantages of true event streaming architectures, lets see how we can leverage these advantages to add value to our business. This is where we can start to build our data catalogue, creating new, trustworthy data sets that we can share with other teams and services. With Flink embedded into our environment, we can apply these concepts in meaningful ways.
We have an enriched data stream of orders joined with customer data, was can use this data to create new data products to share with teams and services. Below we have a simple query that aggregates the order countries of origin and ranks them, returning the top 5 countries from which orders are placed.
WITH country_counts AS (
SELECT country, count(country) as c_country FROM logistics_orders GROUP BY country
)
SELECT country, c_country, row_num
FROM (
SELECT *,
ROW_NUMBER() OVER (ORDER BY c_country DESC) AS row_num
FROM country_counts
)
WHERE row_num <= 5
Navigating the Flink workspace, we can run the query interactively as our data generator is running. The query updates in real time as orders are placed as rankings change.
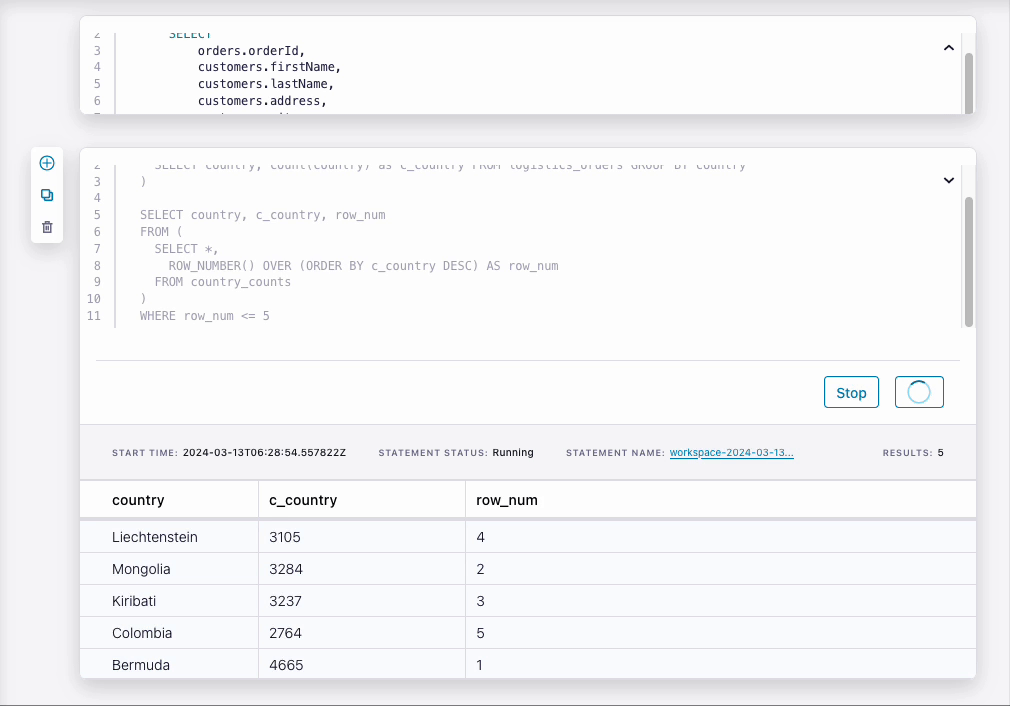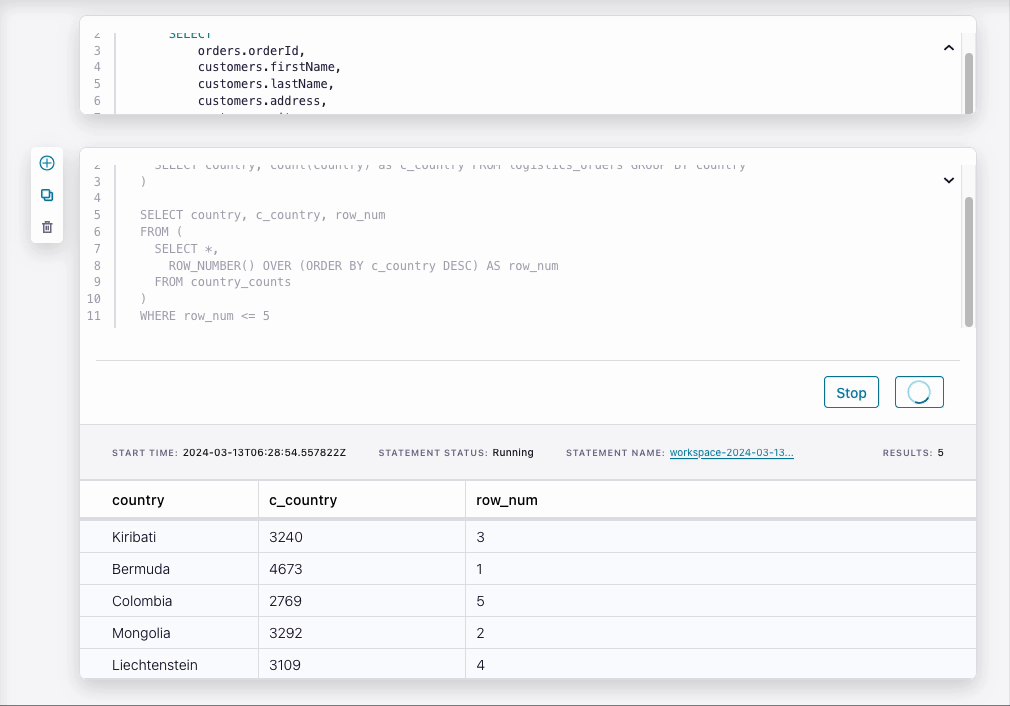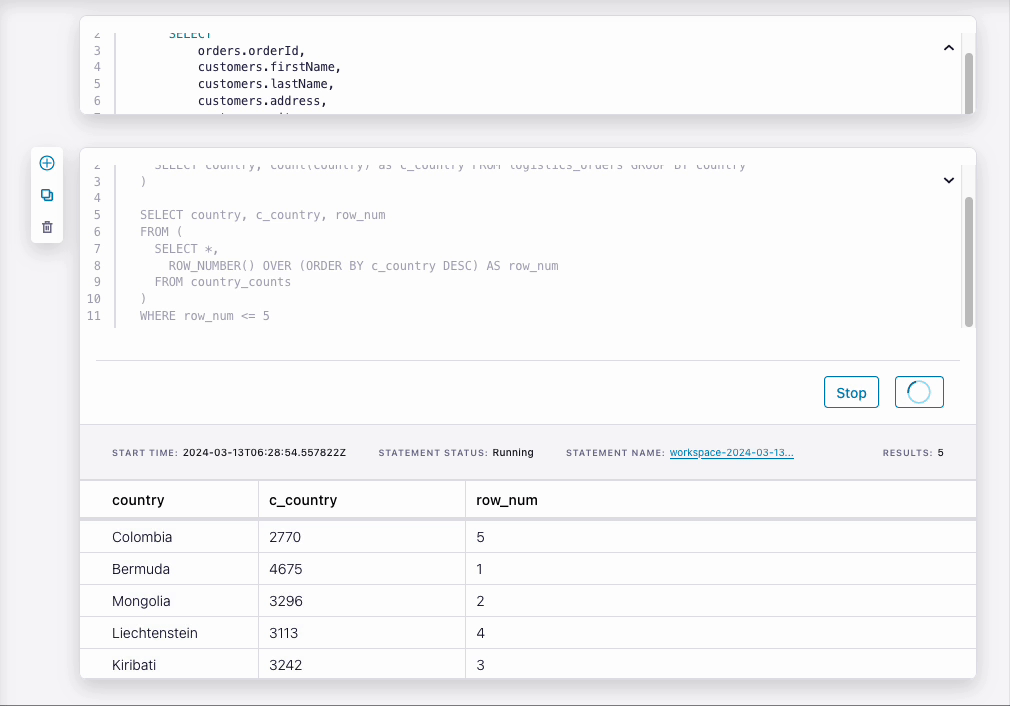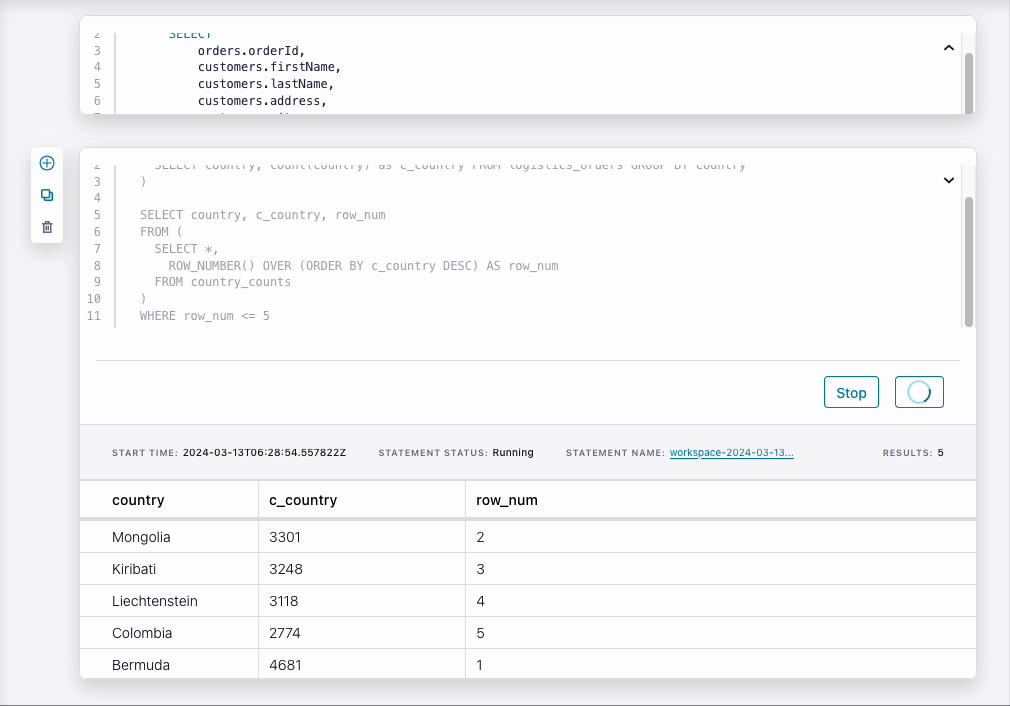
Performing the same query in a Kafka Streams up would require far more code for the same result, whereas our engineer will be able to do the same with Flink in only minutes!
Debriefing
If we examine our new architecture, we can see that we have brought the processing logic for our system, closer to the data it handles. Moving forward we can easily operate on data where it resides. When compared to the original architecture, notice we have encapsulated all of our event streaming capabilities within our streaming environment. By shifting the responsibility of our stream processing applications, onto Flink, we have streamlined our ecosystem. As our system grows we can reap the rewards with the inherent scalability and resilience that comes with this approach.
You can find the code shown in this blog here. You will find everything you need to spin up your own Confluent Cloud environment and try this example out for yourself. You will have a chance build and experiment with cloud native stream processing tools, absolutely free.
Happy Building!