
Introduction
My first introduction to Azure Bicep involved creating a large repository of Azure Bicep deployment templates. I was able to see firsthand the benefits of using Bicep to simplify Azure deployments. Recently I have utilised Azure Data Factory (ADF) for integrating a new enterprise solution. It is an effective data integration tool which streamlines data processing. Due to my experience with both technologies and the growing adoption rate of Bicep and ADF, I decided to document and share my experiences on both.
This article intends to cover a sample Bicep deployment of an Azure Data Factory along with linked services and an integrated repository. Alongside this demonstration will be explanations of the basics of ADF, Git integration, using Bicep to deploy an ADF and restrictions that arise when utilising it or any other infrastructure as code (IaC) tools to deploy an ADF with an existing repository.
What is Azure Data Factory?
- At its core, ADF is a platform for manipulating and integrating data.
- For developers it has a powerful graphic user interface (GUI) for creating ADF components with the option to edit the source code specifying components directly if preferred.
- Its power lies in its ability to scale-out and integrate with multiple data sources and compute resources.
- More information can be found in the Official Microsoft Azure Data Factory documentation
Git integration and Azure Data Factory
- Git is the industry standard for versioning of code. While understanding Git is not vital for understanding this sample deployment, I would heavily recommend reading an overview specifically versioning as it is an integral part of source control if you have no experience with it.
- Azure Data Factory allows for effortless source control when integrated with a Git repository. Without integrating a Git repository there is no source control and all changes will be directly published which is not good practice.
- Here is an overview by Microsoft on how to setup source control for an Azure Data Factory manually as it will be handled by a bicep deployment in this article.
What is Azure Bicep?
- Azure Bicep is an IaC tool that sits above the native Azure Resource Manager (ARM) templates to make the deployment of Azure services more manageable and readable.
- Its main benefits over other IaC tools are that it does not require any state file to be declarative and it is free to use and open source.
- Its main drawbacks are due to it being an Azure specific tool and that it is relatively new and as such has little adoption when compared to competitors like Terraform.
- More information can be found in the Official Microsoft Azure Bicep documentation.
Deployment Overview:
The final deployment will resemble the diagram below: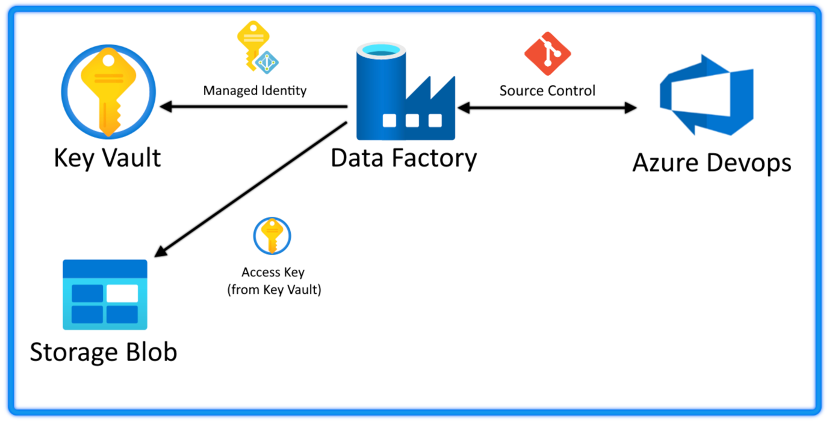
The completed deployment in Azure will contain:
- The Azure Data Factory itself
- A storage account with a Blob container
- A Key Vault containing an access key to the storage account as a secret
- A managed identity we will assign to the ADF with the Role-Base Access Control (RBAC) role security reader, allowing the ADF to read secrets in our Key Vault
On the side is a repository for the ADF to integrate with – while it is possible to migrate and use the same repository to handle infrastructure deployments, I would recommend keeping it separate from your Bicep deployment scripts to prevent developers from modifying deployment templates and exposing secrets.
The templates provided can be separated into two sections: basic infrastructure and additional configuration.
Bicep Templates
The templates provided can be separated into two sections: core infrastructure and additional configuration to give the ADF access to linked services.
The basic Infrastructure will be deployed in parallel without dependency:
- Deploying the Blob Storage Account as a sample linked service.
- Deploying the Key Vault, which will store the secret for the access key to the Blob Storage Account.
- Deploying a User Assigned Identity
Then configuration will be deployed once the associated resources have been deployed:
- Once the User Assigned Identity has been deployed, the ADF will be deployed using the ID of the User Assigned Identity deployed previously.
- Once the Key Vault and the User Assigned Identity have been deployed, the User Assigned Identity will be given a role assignment to read secrets in that Key Vault.
- After the Key Vault and storage account have been deployed, a storage account access key will be added to the Key Vault as a secret.
An example deployment template is provided to show these dependencies.
Deploy Blob Storage Account
This is a standard deployment script for a Blob Storage Account.
Deploy Key Vault
This is a standard deployment script for a Key Vault.
Deploy User Assigned Identity
This deploys a simple User Assigned Identity. The Principal ID is output as a means of easily assigning the Key Vault secret reader role later on.
Deploy Azure Data Factory
This is a modified deployment script for an Azure Data Factory with an integrated git repository and a User Assigned Identity. This module depends on the User Assigned Identity shown prior.
Adding Blob access key to Key Vault as a secret
Adding the Blob access key to the Key Vault as a secret. Depends on the deployment of both the Blob Storage Account and Key Vault in order to reference both.
Deploying Key Vault role assignment
Deploys a role assignment to the User Assigned Identity deployed earlier, which should be configured to allow access to the Key Vault secrets to resources with this role. The specific role for reading Key Vault secrets is shown in the example deployment script. This module depends only depends on the deployment of the Key Vault and can happen in parallel with the ADF deployment.
Setting up linked services
While it is possible to deploy ADF components via Bicep, I would not recommend it as it will conflict with the Git integration and be overridden. Therefore, in the next steps we will be setting up the linked services for the Data Factory manually, opposed to via a Bicep deployment which would be overridden. These will be preserved in the Git repository. Consider reviewing how to set up a linked service using the GUI for a direct walkthrough as this section will cover configurations specific to the deployments above.
Your Key Vault linked service configuration should look like the following:
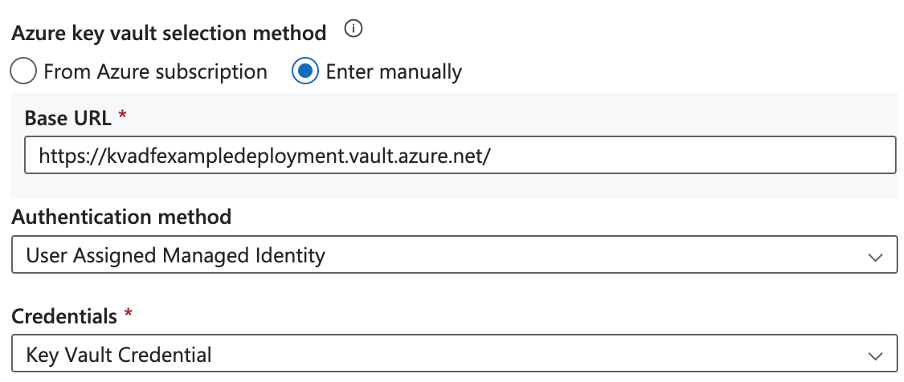
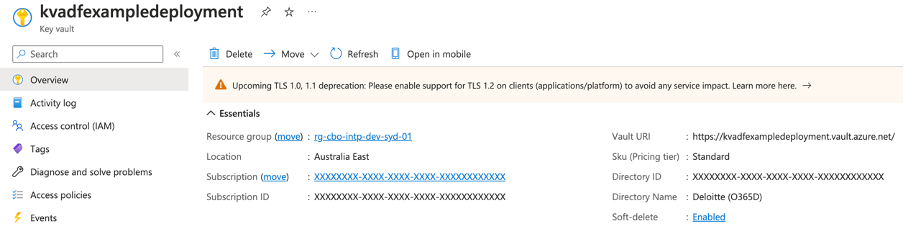
You can find the base URL under your Key Vault overview, as “Vault URI”:
The Authentication Method should be User Assigned Managed Identity deployed previously.
You can create a new credential using the following configuration:

You can then add another connection for the Azure Blob storage using the access key retrieved from the Key Vault:
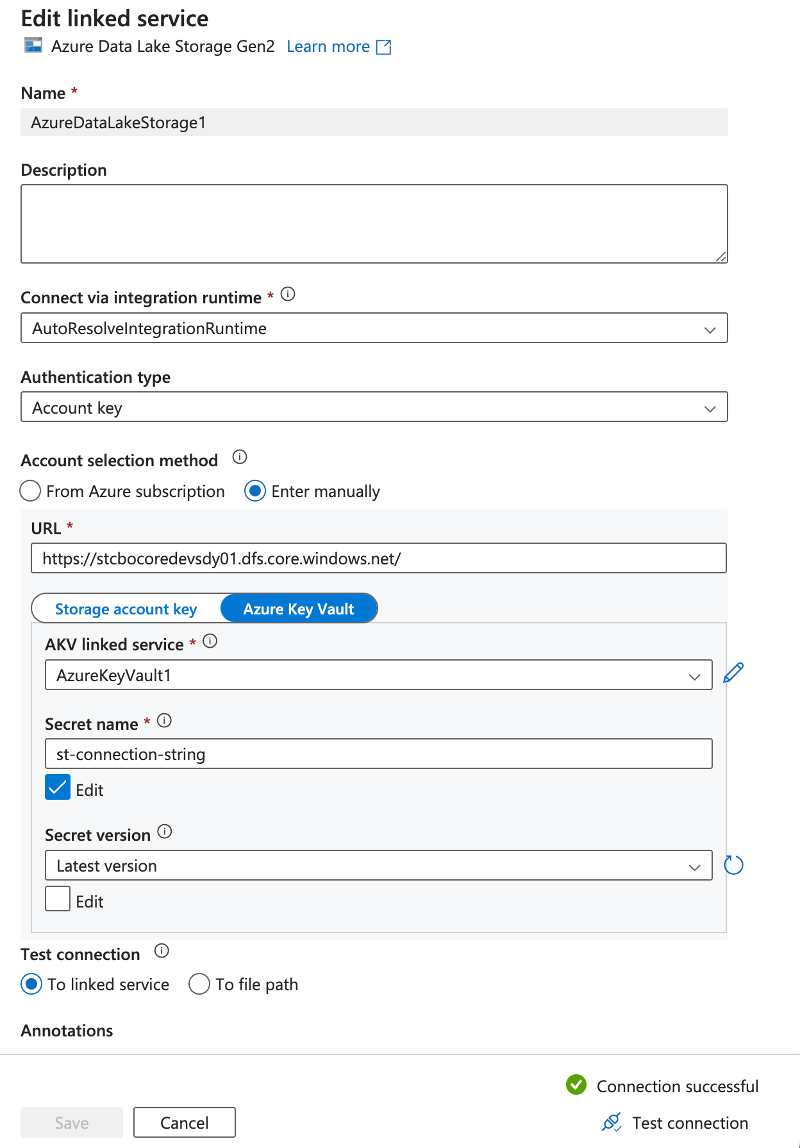
Ready to create
Now your ADF is complete and ready to use. You can now redeploy the ADF and shared resources with ease, along with any created pipelines and activities added to your ADF via the developer interface. To verify the deployment, you should try creating some pipelines on ADF, then delete all resources before rerun the Bicep deployment. Upon redeploying the resources, you may have to alter the name of your Key Vault due to Azure protection preventing a new Key Vault with the same name from being deployed for several days after its deletion. This change will not follow through to the linked service saved in your repository.
Wrapping up
Hopefully this has inspired you to learn more about Bicep or Azure Data Factory as both are powerful tool. I would recommend using this exercise as an intro to the vast topics of Bicep deployment and ADF development which were lightly touched. For more information or help with any integration dilemmas, reach out to our team or have a look through our other blogs.