I recently used Mule ESB with Amazon's Simple Queue Service (SQS) as the supporting messaging infrastructure. Whilst I was able to achieve a reliable outcome that satisfied all requirements, there are a number of aspects of SQS that make it different to the typical JMS-based messaging system. In this post I’ll cover these key points of difference and walk through an example of a robust and reliable Mule flow that can be applied to a range of common integration scenarios.
Take the use case where we want to receive a message on an SQS queue and then ‘reliably’ forward it to an HTTP endpoint. We have the following non-functional requirements:
- We don’t want to lose any messages.
- The HTTP endpoint can potentially be down for a period of time and our flow should be resilient to this.
- It’s not okay to send duplicate messages to the endpoint.
- Any messages that we are either unable to process or consider ‘poison’ should be pushed to a dead letter queue (see point 1).
Start with the simplest solution possible.
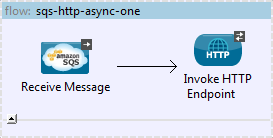
The flow above uses Mule ESB’s SQS connector to read a message from the queue and forward it to an HTTP endpoint. We can add some resilience to this flow simply by wrapping the HTTP endpoint in an until-successful scope.
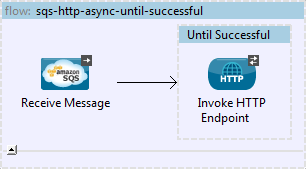
In the simplest sunny day scenarios this would be all that you need, but let’s analyse things further…
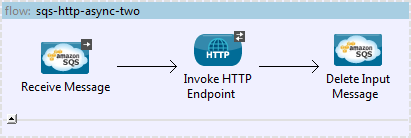
First, SQS relies on the HTTP transport to GET and POST messages to queues. When we’re receiving from SQS, we set a poll interval which specifies how often the application should check the queue for new messages. Because of this, interaction between our application and the queue is connectionless. Once a message is read it sits 'in limbo' until it's been accepted into the control of the until-successful loop. Why is this a problem? By default an SQS message is removed from the queue when it is read, so if the receiving flow either crashes or is restarted when a message is in flight it means we can lose the message. Even if we configure the until-successful scope to use an object store, we still have a window between receiving a message from the queue and the until-successful scope being invoked where messages can be lost. A nice solution is to take advantage of the ‘Retain messages on input queue’ parameter of the SQS ReceiveMessages operation which specifies that the message is to be left on the queue after it is read. This addresses message loss, but now we must explicitly delete the message from the queue at the end of the flow.
Second, when we receive from SQS we supply a ‘VisibilityTimeout’, which is the duration (in seconds) that the received message is hidden from subsequent read attempts. Whatever value we set here, we need to be very confident that any downstream processing will be completed within this timeout period. If we set this incorrectly, the message is open to being consumed by another instance of the flow and we open ourselves up to potentially delivering duplicate messages to the endpoint. For the scenario above, we set a timeout of 10 seconds on the HTTP request and a Visibility timeout of 30 seconds just to be safe.
The updated flow removes the until-successful scope and explicitly deletes the input message once we’re finished processing.
(You can view the current properties file for the app here).
So we’ve now built a bit of resilience into our flow and partially addressed a couple of important non-functional requirements. The next issue is error handling. The new flow doesn’t work very well if there is a problem with the HTTP callout, or if we fail to delete the input message. Once we’ve received the message from the input queue, under certain error scenarios such as an error returned from the endpoint or we receive a poison message, the VisibilityTimeout will kick in after 20 seconds and the flow goes into an infinite loop with the message being replayed over and over. This is not good - it doesn’t matter how many times we replay the message, it will never be successful! We need to add retry and exception handling.
We’ll need to add an exception strategy to our flow, introduce the concept of a Dead Letter Queue (DLQ) and make use of the following additional properties:
- ApproximateReceiveCount - Is an SQS message property that returns the number of times that SQS thinks a message has been received but not deleted. Due to the distributed nature of SQS, a lot of things are approximate and Amazon openly provides no guarantees of precision. We rely on this property in our application, but also accept the fact that its value may not be exact.
- MaxReceives - Is our own property (defined at the application level) is used to specify the maximum number of times we want to receive messages from the queue before considering them a failure.
- Dead Letter Queue – Is a queue defined for this flow where we push any messages that we consider to be undeliverable.
Our application properties file now looks like this. Let’s update our flow as follows:
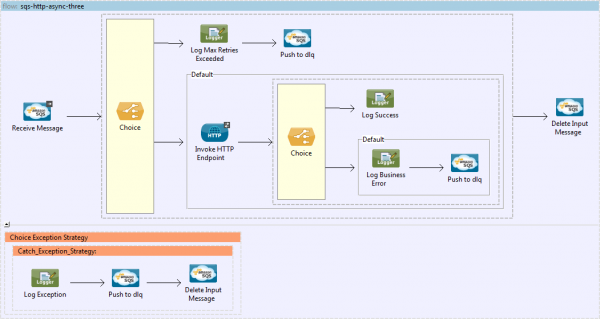
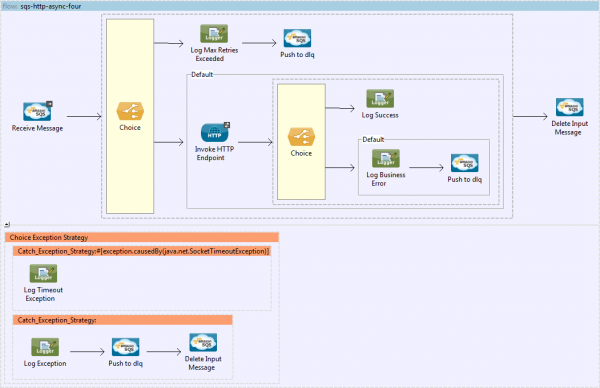
It may seem like there's a fair bit going on here but let's break it down...
- We’ve added a Choice that checks the ApproximateReceiveCount property of the received message and compares this to our MaxReceives property.
- If MaxReceives is exceeded, we push the message to the DLQ.
- Otherwise, invoke the HTTP endpoint as before.
- Another Choice follows the HTTP callout to check the status code returned from the endpoint.
- If the status code is 200 our request was successful, log this fact, then explicitly delete the input message.
- Otherwise, log that our endpoint returned an error (considered non-retriable for our application), push the message to the DLQ, then delete the input message.
- There’s also a blanket Catch Exception Strategy catches any exceptions and pushes the message to the DLQ.
But there’s still one key area that we haven’t touched on – how do we handle when the HTTP endpoint is down for an extended period of time? We want the flow to be resilient to this so we add a couple of important extra features:
- The exception strategy should differentiate between non-retriable (i.e. poison messages) and retriable exceptions such as timeouts with the HTTP endpoint.
- Define VisibilityTimeout and MaxReceives properties that get us close to the maximum amount of time we can expect the endpoint to be down at any one time. If we increase these properties to say, 60 and 30 respectively, this allows 30 minutes for the endpoint to recover before we start pushing messages to the DLQ. Handling outages longer than 30 minutes requires escalation processes. We could manually or automatically detect the outage and suspend the flow. We may also need a mechanism to inspect and replay messages that end up on the DLQ in the event of an outage.
One final consideration here is to make sure the flow is configured with a processing strategy that doesn’t flood the endpoint with messages when it recovers after a lengthy outage. A custom asynchronous processing strategy with the ‘Max Threads’ property set appropriately and limiting the number of messages we pull from the input queue with each receive, will allow Amazons infrastructure to absorb the load while the endpoint is down. The flow can then process messages at a comfortable rate when it recovers.
The updated flow now looks like this:
(You can view the XML version here and the properties file for the app here).
This flow assumes that a java.net.SocketTimeoutException is the only type of exception that we'd ever want to retry, it’s easy enough to modify the exception strategy to cater for any number of scenarios. The key thing to note is that we don't need to explicitly push our message anywhere to have it retry. By allowing the flow to complete processing, we let the VisibilityTimeout period kick-in automatically - at which point the message will be replayed through the flow up until the point that it is either successful, or the value of our MaxReceives property is exceeded.
We now have a flow that reliably forwards messages from SQS to an HTTP endpoint with errors going into a DLQ for manual recovery. There are still two missing pieces however: we can still have duplicate messages in some edge-cases, and SQS doesn’t guarantee message order. These are difficult problems in distributed systems and rely on application level techniques that we’ll discuss another time.