
Many organizations are adopting a microservices architecture in order to reduce dependencies between system components and allow more frequent release cycles and more flexible scalability. However, unless they have a clear view of the underlying interaction patterns, teams risk building a tightly coupled distributed monolith.
This article introduces patterns that underpin microservice interactions and explains how event streaming enables an Event-Driven Architecture (EDA) to support the microservices principles around loose coupling.
The Maturing Microservices Landscape
Typically teams start the journey with a small set of microservices and a limited number of interactions between them. As the number of microservices grow, so do the interactions between them. Understanding these interactions is crucial to maintaining loosely coupled microservices.
As architects, we need to worry much less about what happens inside the zone than what happens between the zones - Building Microservices (Sam Newman)
A step towards reasoning about these interactions is categorising them into Commands, Queries and Events.
| Commands | Events | Queries | |
|---|---|---|---|
| Definition | Commands are something we want to happen | Events are something that have happened | Queries are requests to look something up |
| Produce-Consumer relationship | A one-to-one connection between a producer (who sends the command) and a consumer (who takes and executes the command) | It’s sent by a publisher who doesn’t know and doesn’t care about the (0-N) subscribers of the event | A one-to-one interaction between a requester (who submits the query) and responder (who responds with query results) |
| Effect on system state | Commands change system state. Typically the sender is interested in the result | Events are notifications of a state change in the system. Subscribers are interested in this information. | Queries do not change the observable state of the system (are free of side effects). The requester is interested in the result |
| Interaction Pattern | Well-suited for request-response pattern | Well-suited for publish-subscribe pattern | Well-suited for request-response pattern |
While many organisations have become proficient at implementing commands and queries using modern APIs, most are yet to leverage the benefits of event-driven architectures.
In growing ecosystems, where services need to evolve independently, commands and queries add much coupling, tying services together at runtime. Events help alleviate this tight coupling while still facilitating collaboration between services.
Synchronous calls considered harmful - Microservices (Martin Fowler)
HTTP APIs Need a Companion
HTTP is a synchronous, request-response protocol, where the client sends a request to a known server and is expecting a response from the server; it assumes the server is available and able to respond. This interaction style is well suited to implement commands and queries but does not lend itself to event-based communication. Event-based communication is best achieved using the publish-subscribe pattern.
Events represent an invaluable combination of notification and state distribution.
Event = Notification + State
Events give applications a choice: continue with command and queries OR embrace events to trigger their processes and reference the events to extract data for their private use.
As service eco-systems grow, architects are well-advised to model events as first-class citizens and think about the significant business facts that services need to share with the outside world.
Organisations often struggle with identifying significant events within their business processes. Event Storming workshops can help overcome this initial hurdle, as they are fun, free-flowing workshops which bring together developers and domain experts with the goal of expressing business processes as a series of significant events.
Not all events are equal, some events don’t evoke reactions; however the most significant events evoke reactions, and these events should be modelled in our software systems.
Embracing events lessens your dependency on commands and queries. Events transfer state between services reducing the need for queries between them. They also notify services of significant events occurring in the broader ecosystem, enabling services to react appropriately and thereby offering an alternative to command-style interactions for triggering business processes.
Events notify of a state change. Commands cause a state change.
Persisting Your Event Streams
Even with events transferring state across services, subscribers need to store a representation of the event stream to avoid remote queries. These local data stores must be kept in sync as new events get published and as the number of data stores increase so does the probability of data-drift.
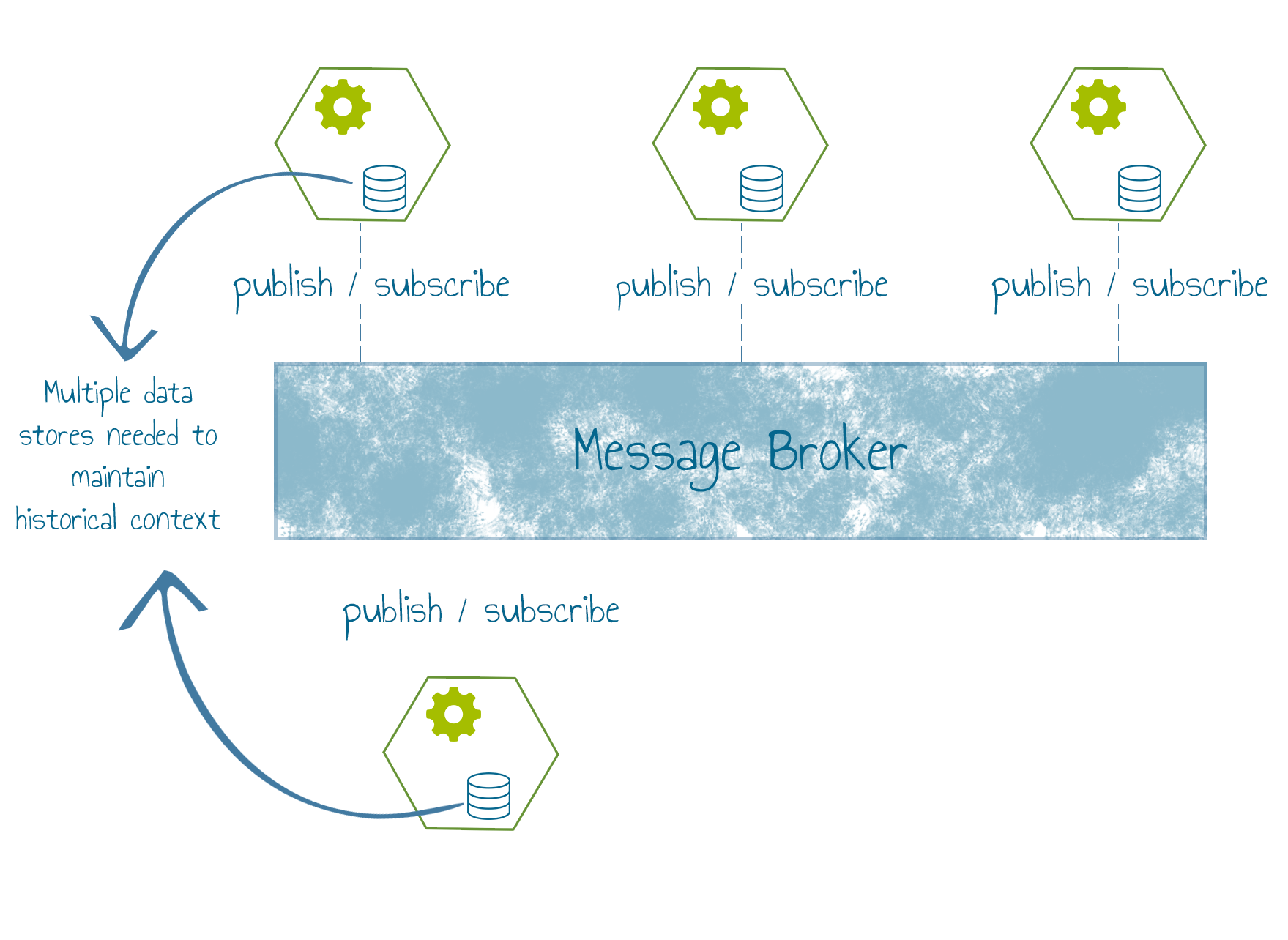
Persisting the event stream enables services to directly reference the shared event stream and create their own private views from them. They no longer have to store copies of the events locally.
In addition to alleviating some of the complexities, event streaming begins to offer new opportunities. The resulting historical reference is something new services can plug into and is a powerful bootstrapping tool that opens the architecture to extensions.
A central log of facts that services can reference is bound to pay high dividends.
This type of persistent event stream can be implemented as a Distributed Commit Log.
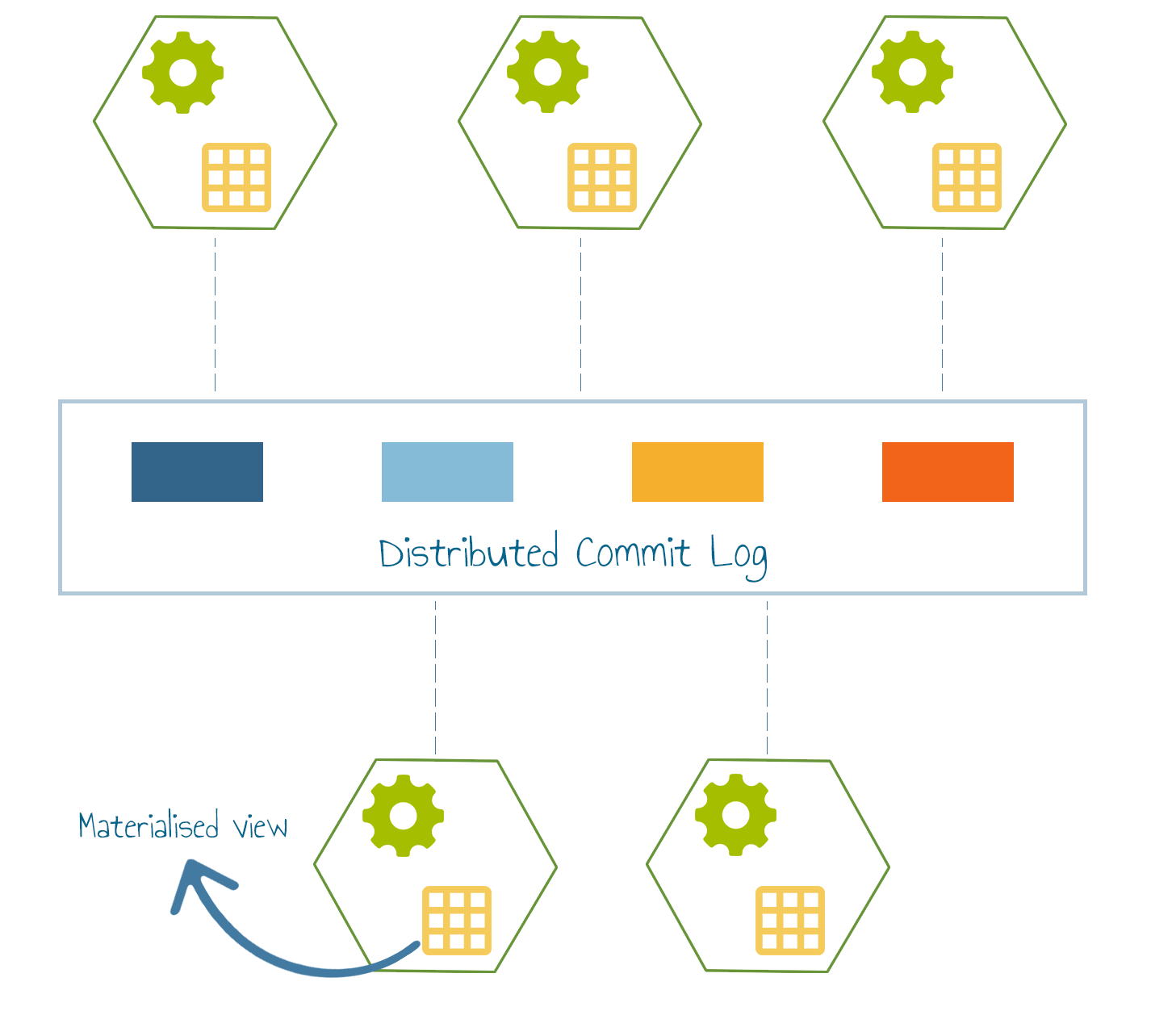
Admittedly the promise of Event Driven Architecture has been around for a long time, but it is the Distributed Commit Log foundation that makes things different this time and unleashes its real potential.
A distributed commit log is conceptually similar to a database transaction log, sometimes referred to as write-ahead logs or commit logs which are a history of actions executed by a database management system.
The distributed commit log decouples the consumption of the message from the storage of the message. This decoupling affords many benefits, the three most relevant to event-driven architectures are
-
Source of truth: The log can become a source of truth. Events are permanently stored in the log and can be referenced by subscribers at any time.
-
Event Replay and Audit Trail: As events are immutable and permanently stored you get auditing, monitoring and event replay by default. In addition to allowing existing subscribers to replay the event history, it also lets new subscribers plug into the event stream and consume past events.
-
Stream processing: Processing data in the commit log enables real-time business insights even before the data has landed into an analytics engine.
Event Driven Architecture (EDA) based on Distributed Commit Logs enables organisations to scale out their Microservices Architectures and derive real-time insights from the data exchanged between services.
EDA is the next stage in the Microservices Architecture evolution, and unsurprisingly every major vendor like Google, Azure, Hortonworks has tooling to support this evolution.
Apache Kafka is a widely adopted implementation, and there are also cloud-native solutions like AWS Kinesis.
Final Thoughts
Microservices are gaining importance within organisations, and the data exchanged between these services is invaluable, architecting to leverage this data gives organisations a competitive edge and is the next logical step in the Microservices evolution.