
A billion dollars used to be a lot of money. These days it can buy you a small social network, a sports team or perhaps a high profile IT project disaster. ComputerWorld's round-up of top IT disasters for 2013 leads with the Healthcare.gov debacle, but Australia proves its world-class chops with the Queensland Health payroll upgrade project; number two with an estimated cost of A$1.25 billion. These big project failures have many contributing causes and there are some good commission reports to learn from, but undoubtedly a major problem is their sheer size and scope.
The Standish Group has been analysing IT project success and failure for many years and annually publishes its well-known CHAOS Report. There is clearly a significant difference in the failure rates for large versus small projects. The CHAOS Mainfesto 2013 (PDF) reports that in 2012 small projects - those with less than US$1 million in labour content had a 76% success rate. Large projects with more than $10 million in labour content had only a 10% success rate. The difference is stark.
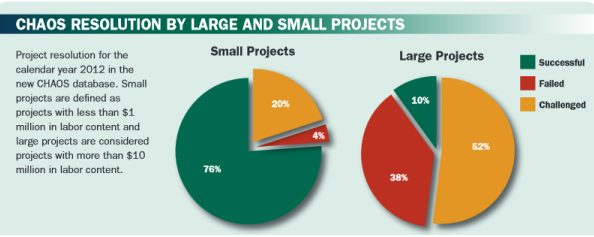
The report states that "...more companies are recognizing that a small project optimization solution is highly effective. The quick solution is to just say no to large projects, but the more sensible answer is to adopt a small project strategy." So why can't we just say no to large projects?
Poor planning and lack of management continuity is one issue. Systems languish and are neglected until problems become critical. Then remediation projects are subjected to urgencies and stress that further contribute to their failure. Big projects also suit certain business models: ambitious managers want to make a big impact before their next step, large vendors want headline case-studies and lots of chargeable bums on seats. But these are mostly political causes. Technical contributions to big projects come back to the tight coupling of IT systems.
Tightly coupled systems are hard to change, so people avoid and postpone any change. Technical debt builds and builds until the system verges on failure. Drastic action—emergency surgery akin to a heart and lung transplant is required—the whole tightly coupled furball has to be replaced in one go. Tragically it is often replaced by another furball, the so-called "like for like replacement." Modernization is not optional and a systematic approach needs to be taken with respect to systems change management.
Earlier I talked about how layered architectures can help manage change.
- A focus on composable services and processes rather than monolithic applications changes the business architecture focus into units that are more manageable, that are under the control of the organization, that can be planned and roadmapped over the appropriate time horizons.
- The business accesses application functionality through a service abstraction layer, underlying applications can be maintained, upgraded and changed with lower impact on the business. Complex feature migrations can be handled incrementally by redirecting services from one back-end implementation to another. As long as the interfaces don't change, noone needs to know the difference in the back-end. I've seen this approach work well for huge migrations of back-end systems from mainframes to more modern architectures.
- Implementing differentiating business processes and rules in an independent layer above the application layer allows processes to change without drilling into static systems. Change is generally easier in an independent BPM layer than it is to modify or customize off the shelf applications. Application customization is a quick way to build mountains of technical debt that stop future upgrades.
- Service versioning is a critical enabler of change. It allows different consumers to work with the version of their choice and to migrate to newer versions at times that naturally suit their maintenance cycle. Managing services as a "product," which includes versioning and lifecycle management, avoids the tight coupling problems that force all parts of an enterprise to change in lock-step—the very thing that leads to big bang projects.
This is one of our foundational beliefs at Deloitte Platform Engineering, that IT success is best obtained through planning, collaboration and incremental change. Big bang projects? Just say no!